최근 딥러닝을 공부하다 마침 테스트 해보기 좋은 주제가 있어 이렇게 글을 남긴다.
기존의 이미지 판별기 역할을 했던 CNN (Convolutional Neural Network) 라는 모델을 가지고
텍스트 데이터에 적용하여, 한국어 혐오글 분류기를 만들어 보고자 한다.
다른 블로그에서도 충분히 다뤘지만 애처롭게도 torchtext의 버전업이 되면서 deprecated된 내용들이 너무 많아 내가 다시 작성했다.
torch=2.2.1
torchtext==0.17.0
lightning
혐오 데이터셋은 여기에서 다운 받았다.
데이터셋의 예시는 아래와 같다.

def tokenize(sentence):
tokens = tokenizer.tokenize(sentence)
preprocess = lambda x: [w for w in x if w not in STOP_WORDS]
return preprocess(tokens)
이런식으로 토크나이저를 구성하면 된다. (이 글의 경우 word2vec 토크나이저를 사용했다.)
df['tokens'] = df['comments'].apply(tokenize)
# 공격적인(offensive) 댓글 또한 혐오 데이터 셋으로 분류함.
df['hate'] = df['hate'].replace(['none', 'offensive', 'hate'], [0, 1, 1])
df['contain_gender_bias'] = df['contain_gender_bias'].replace([True, False], [1, 0])
dataframe에 ‘tokens’ 피쳐를 따로 만들어 준 다음 댓글 내용을 tokenise 해준다.
hate 여부의 경우 offensive와 hate 모두 같은 분류로 처리 해 주며 contain_gender_bias 역시 boolean 값을 1, 0로 바꿔준다.
vocab = set()
for sentence in df.tokens:
for word in sentence: vocab.add(word)
vocab_size = len(vocab)
이런식으로 모든 단어의 갯수를 세어 준다음 vocab_size를 계산해준다.
df['encoding'] = df['comments'].apply(vectorizer.encode_a_doc_to_list)
df.encoding
벡터에서 tokenised 된 단어들을 모두 인코딩으로 고쳐준다.
X_data = df['encoding']
y_data = df['hate']
이제 인코딩 데이터와 hate 여부 (y label)를 데이터 셋으로 불러준다.
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=.1, random_state=0, stratify=y_data)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=.1, random_state=0, stratify=y_train)
이렇게 train, test, valid 셋을 따로 구별해 준다.
댓글 마다 모두 단어들의 크기가 전부 다르다. 어떤 문장은 10단어가 있을 수도 있고, 또 어떤 문장은 50단어가 있을 수도 있다. 그렇기 때문에 어떤 기준을 잡아 그 길이를 기준으로 쳐내거나 빈값을 추가해 줘야 한다. (패딩)
def pad_sequences(sentences: [[int]], max_len: int) -> np.ndarray:
features = np.zeros((len(sentences), max_len), dtype=int)
for index, sentence in enumerate(sentences):
if len(sentence) != 0:
features[index, :len(sentence)] = np.array(sentence)[:max_len]
return features
padded_X_train = pad_sequences(X_train, max_len=max_len)
padded_X_valid = pad_sequences(X_valid, max_len=max_len)
padded_X_test = pad_sequences(X_test, max_len=max_len)
x 데이터에 대해서만 패딩을 진행 해 주면 된다.
train_label_tensor = torch.tensor(np.array(y_train)) valid_label_tensor = torch.tensor(np.array(y_valid)) test_label_tensor = torch.tensor(np.array(y_test))
그 데이터를 모두 텐서화 한 다음에
def train_dataloader(self):
encoded_train = torch.tensor(padded_X_train).to(torch.int32)
train_dataset = TensorDataset(encoded_train, train_label_tensor)
train_dataloader = DataLoader(train_dataset, shuffle=True, num_workers=7,
persistent_workers=True, batch_size=self.train_batch_size)
return train_dataloader
def val_dataloader(self):
encoded_valid = torch.tensor(padded_X_valid).to(torch.int32)
valid_dataset = TensorDataset(encoded_valid, valid_label_tensor)
valid_dataloader = DataLoader(valid_dataset, shuffle=False, batch_size=1, num_workers=7,
persistent_workers=True)
return valid_dataloader
def test_dataloader(self):
encoded_test = torch.tensor(padded_X_test).to(torch.int32)
test_dataset = TensorDataset(encoded_test, test_label_tensor)
test_dataloader = DataLoader(test_dataset, shuffle=False, batch_size=1, num_workers=7)
return test_dataloader
다음과 같이 데이터 셋을 준비해 주면 된다. (기타 parameter들은 알아서 쉽게 유추할 수 있을 것이라 생각한다…)
class TextCNNLightning(L.LightningModule):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout, train_batch_size):
super().__init__()
self.lr = None
self.train_batch_size = train_batch_size
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [batch size, sent len]
embedded = self.embedding(text) # embedded = [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1) # embedded = [batch size, 1, sent len, emb dim]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
# conv_n = [batch size, n_filters, sent len - filter_sizes[n]]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
lightning (구 pytorch_lightning) module을 이용해 CNN 모델을 만들었다.
embedding 사이즈는 vocab_size를 input으로 그 다음 레이어에서 출력값으로 embedding_dim을 설정하면 된다.
여러 convs를 클래스 initialiser에서 받은 list에서 가져와서 설정한다. (hyper parameter)
그리고 나머지는 논문에 따라 나머지를 구성해 주면 된다.
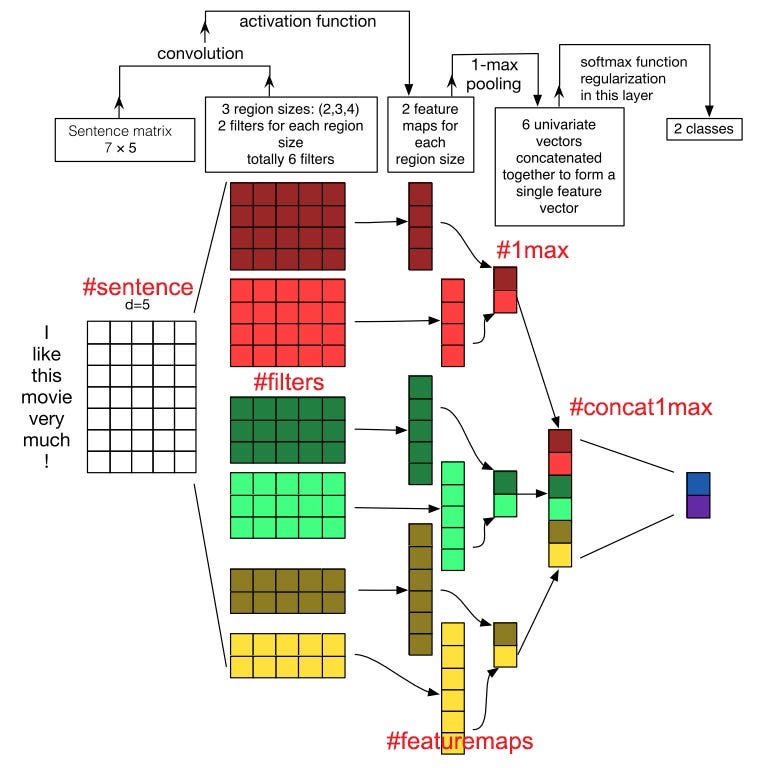
그러면 이런식으로 conv와 pooling, fully connected 레이어를 거쳐 새로운 모델을 만들 수 있다.
# Calculate loss
loss = F.cross_entropy(outputs, labels)
loss는 CEE로 설정했고
def __accuracy(self, outputs, labels):
predictions = outputs.argmax(dim=1) # Get indices of highest probability
correct = (predictions == labels).sum().item()
acc = correct / len(labels)
return acc
accuracy의 경우 이렇게 구현했다.
model = TextCNNLightning(vocab_size=vocab_size, embedding_dim=300, n_filters=100,
filter_sizes=[3, 4, 5], output_dim=2, dropout=.5, train_batch_size=512)
hyper parameter의 경우 다음과 같이 설정해 줬다.
test_acc 0.6463560461997986
test_loss 0.7093809247016907
정확도는 64%이고 손실률은 0.7이 됐다. 손수 직접 임베딩을 한 것이라, 아무리 epoch를 더 돌린다 해도 정확도가 더 올라가지 않아 포기했다. HPO 관련 라이브러리를 설치해봤으나 시간이 너무 부족해 hpo는 하지 못했다.